Notes on resolvability of user and group names
User names, UIDs, group names and GIDs don’t have to be resolvable using NSS
(i.e. getpwuid() and getpwnam() and friends) all the time. However, systemd
makes the following requirements:
System users generally have to be resolvable during early boot already. This
means they should not be provided by any networked service (as those usually
become available during late boot only), except if a local cache is kept that
makes them available during early boot too (i.e. before networking is
up). Specifically, system users need to be resolvable at least before
and are started, as both
need to resolve system users — but note that there might be more services
requiring full resolvability of system users than just these two.
Regular users do not need to be resolvable during early boot, it is sufficient
if they become resolvable during late boot. Specifically, regular users need to
be resolvable at the point in time the unit is
reached. This target unit is generally used as synchronization point between
providers of the user database and consumers of it. Services that require that
the user database is fully available (for example, the login service
) are ordered after it, while services that provide
parts of the user database (for example an LDAP user database client) are
ordered before it. Note that is a passive unit: in
order to minimize synchronization points on systems that don’t need it the unit
is pulled into the initial transaction only if there’s at least one service
that really needs it, and that means only if there’s a service providing the
local user database somehow through IPC or suchlike. Or in other words: if you
hack on some networked user database project, then make sure you order your
service and that you pull it in with
. However, if you hack on some project that needs
the user database to be up in full, then order your service
, but do not pull it in via a
dependency.
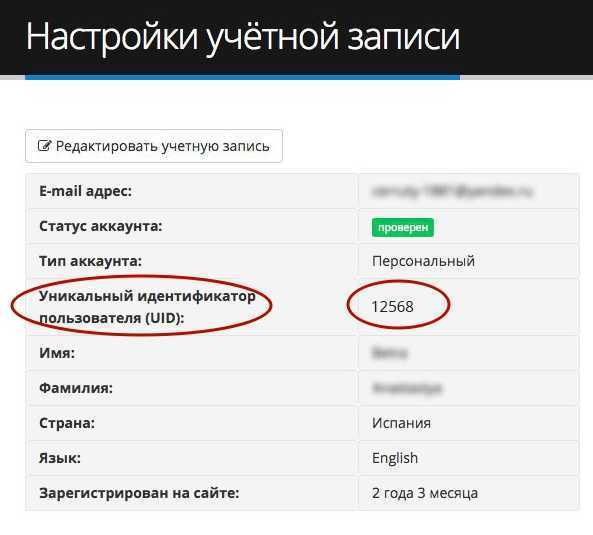
Что такое UID в SQL: Подробное объяснение
В SQL, UID (уникальный идентификатор) является уникальным значением, которое присваивается каждой записи в таблице базы данных. UID помогает идентифицировать каждую запись в таблице и обеспечивает уникальность данных. В этой статье мы рассмотрим, что такое UID в SQL более подробно и как его использовать.
Зачем нужен UID в SQL?
UID (уникальный идентификатор) имеет несколько важных преимуществ и приложений в SQL:
- Уникальность: Поскольку каждая запись в таблице имеет уникальный UID, это позволяет избежать дублирования данных и обеспечивает целостность базы данных.
- Индексирование: Главным образом, UID используется для создания индексов в базах данных. Индексы позволяют быстро находить и извлекать данные из таблицы.
- Связь: UID используется для создания связей между таблицами. Например, внешний ключ в другой таблице может ссылаться на UID в основной таблице.
- Аутентификация: UID может быть использован для аутентификации пользователей или объектов в системе баз данных.
Как создать UID в SQL?
Существует несколько способов создания UID в SQL, в зависимости от используемой базы данных.
1. Использование автоинкремента:
Автоинкрементное поле является одним из самых распространенных способов создания UID в SQL. Оно автоматически увеличивает значение при каждой вставке новой записи в таблицу.
В приведенном выше примере, поле «uid» будет автоматически увеличиваться при каждой новой вставке записи в таблицу «users».
2. Генерация UID с помощью UUID:
UUID (Универсально Уникальный Идентификатор) является другим способом генерации UID в SQL. Он генерирует уникальное значение, которое очень маловероятно будет дублироваться.
В приведенном выше примере, поле «uid» будет содержать уникальное значение UUID при каждой новой вставке записи в таблицу «users».
Как использовать UID в SQL?
UID может быть использован в SQL для различных операций, таких как вставка, обновление, удаление и выборка данных.
Вставка записей с UID:
При вставке новых записей в таблицу, UID может быть либо автоматически сгенерирован, либо предоставлен пользователем.
В приведенном выше примере мы вставляем новую запись в таблицу «users» с явно указанным значением UID.
Обновление записей с помощью UID:
UID может быть использован для обновления существующих записей в таблице.
В приведенном выше примере мы обновляем имя пользователя в таблице «users», используя условие, что UID равен 1.
Удаление записей с помощью UID:
UID также может быть использован для удаления записей из таблицы.
В приведенном выше примере мы удаляем запись из таблицы «users», используя условие, что UID равен 1.
Выборка данных с использованием UID:
UID может быть использован для выборки данных из таблицы.
В приведенном выше примере мы выбираем все поля из таблицы «users», где UID равен 1.
Как UID связан с различными системными ресурсами? [для опытных пользователей]
UID уникальны друг для друга, поэтому их также можно использовать для идентификации владения различными системными ресурсами, такими как файлы и процессы.
UID и файлы
Надеюсь, вы знакомы с концепцией прав доступа к файлам в Linux. Когда вы создаете файл, вы являетесь владельцем этого файла. Теперь вы можете решить, кто и что будет делать с этим файлом. Это часть механизма DAC Linux, где каждый файл остается на усмотрение его владельца.
Вы можете узнать владельца файла, используя команду ls или stat. Давайте сделаем это с помощью популярной команды ls и проверим принадлежность двоичного файла или .
Как видите, файл /usr/bin/sleep принадлежит пользователю root:
Давайте заставим его сопоставлять право собственности с UID вместо имени пользователя:
Вот забавная информация. Ваша операционная система не понимает «имена пользователей». Всякий раз, когда программе необходимо работать с именами пользователей или распечатывать их, она обращается к файлу для извлечения информации.
Вам не обязательно верить моим словам. Убедитесь в этом сами, воспользовавшись программой strace, которая печатает все системные вызовы, выполненные программой.
Вы пытаетесь узнать, пытается ли команда прочитать файл или нет.
Все идет нормально.
UID и процессы
У процессов тоже есть владельцы, как и у файлов. Только владелец (или пользователь root) процесса может отправлять ему сигналы процесса. Здесь в игру вступает UID.
Если обычный пользователь попытается завершить процесс, принадлежащий другому пользователю, это приведет к ошибке:
Это может сделать только владелец процесса или root.
Процесс должен быть регламентирован. Регулируется, поскольку вам нужно иметь способ ограничить или знать, сколько процессов разрешено делать. Это определяется его UID(ами).








Существует три типа UID, связанных с процессом.
Настоящий UID: Настоящий UID — это UID, который процесс принимает от своего родительского процесса. Проще говоря, кто бы ни запускал процесс, UID этого пользователя является реальным UID процесса. Это полезно для определения того, кому на самом деле принадлежит процесс
Это особенно важно, когда эффективный UID не совпадает с реальным UID, о котором я собираюсь поговорить дальше.
Эффективный UID. Это то, что в основном определяет, какие разрешения действительно имеет определенный процесс
Хотя пользователь может запустить процесс, он может работать с доступными разрешениями другого пользователя. Команда является одним из примеров. Эта программа редактирует файл , который принадлежит . Следовательно, обычный пользователь не должен иметь возможности запустить эту команду или изменить свой пароль. К счастью, двоичный файл запускается с эффективным UID, равным 0 (т. е. root), что дает ему достаточно привилегий для редактирования файла . Реальные и эффективные UID в основном одинаковы, за исключением двоичных файлов с битом SUID.
Сохраненный UID: UID, доступный в распоряжении процесса. Обычно он не используется, но все равно присутствует на случай, если процесс знает, что не будет выполнять никакой привилегированной работы, поэтому он может изменить свой эффективный UID на непривилегированный. Это уменьшает вероятность непреднамеренного неправильного поведения.
Вот и все. Надеюсь, теперь у вас есть лучшее представление о UID в Linux. Не стесняйтесь задавать вопросы, если таковые имеются.
Как профессиональный пользователь Linux, если вы считаете, что я упустил какую-то важную информацию о UID, дайте мне знать об этом в разделе комментариев.
Managing group permissions
When users create files, the user owner gets read (r) and write (w) permissions, the group gets read permission, and others get read permission (rw-r—r—), or in numeric terms, 644. The execute (x) permission is not given by default. So, as a system administrator, if a group member requests execute permission be placed on a file or group of files, then grant execute permission for the group only:
The user can change the permission themselves if they are the user owner but often will not do so for fear of doing it incorrectly. Only the user owner or the root user can change permissions on a file even if the group has write permission to the file. Write permission means that a group member can edit or delete the file.
Be sure that shared group directories have write access (permission) for the group, and that the files that need to be modified by group members also have write access. Some of you who have more advanced permissions knowledge are probably asking why I don’t mention the (change attributes) command, and it’s a valid question. The command is out of scope for this article but will be covered in a later article that focuses solely on and its many options.
Хранилища учетных записей
Информация об идентификаторах UID и GID, именах пользователей и групп, их паролях и прочих свойствах учетных записей размещается (в простейшем случае) в файловых «хранилищах,»-Добычных текстовых файлах каталога /etc, формируя базы данных пользовательских /etc/passwd, /etc/shadow и групповых /etc/group, /etc/gshadow учетных записей. формат и структура этих файлов хорошо документированы в руководстве passwd(5), shadow(5) и group(5), gshadow(5) и представляют собой простейшие текстовые таблицы, где свойства каждой учетной записи представлены набором столбцов одной строки, разделенных символом двоеточия : .
Базы данных пользовательских учетных записей
john@ubuntu:~$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
. . . . . .
dvk:x:1000:1000: Alexey Ivanov,,+7(805) 530-01-04,,:/hone/dvk:/bin/bash
. . . . . .
finn@ubuntu:~$ cat /etc/group
. . .
dvk:x:1000:
lpadmin:x:108:dvk
sambashare:x:109:dvk
admin:x:110:dvk
. . .
При использовании «коммутатора службы имен» (NSS, W: ) имеется возможность хранить базы данных учетных записей в любых хранилищах, включая сетевые службы каталогов NIS, NIS+, LDAP, активный каталог Microsoft Windows и даже реляционные сетевые базы данных SQL— при помощи соответствующих модулей NSS и согласно настройкам коммутатора nsswitch.conf(5).
Хранилища пользовательских учетных записей и модули NSS
john@ubuntu:~$ cat /etc/nsswitch.conf
. . .
passwd: compat
group: compat
shadow: compat
. . .
john@ubuntu:~$ find lib -name ‘libnss_*’
. . .
/llb/i386-llnux-gnu/llbnss_nlsplus.so .2
/lib/1386- linux — gnu/libnss_compat. so. 2

![[ga4] как отслеживать действия на разных платформах с помощью функции user-id - cправка - google analytics](https://vsenazapad.ru/wp-content/uploads/8/a/5/8a5fabc1d1316b0ff38809ae9112eccf.jpeg)




. . .
/lib/i386-linux-gnu/libnss_files.so.2
/lib/l386-llnux-gnu/libnss_nis.so.2
/lib/1386-llnux-gnu/libnss_winbind. so. 2
. . .
Figuring out the system’s UID boundaries
The most important boundaries of the local system may be queried with
:
(Note that the latter encodes the maximum UID base might
pick — given that 64K UIDs are assigned to each container according to this
allocation logic, the maximum UID used for this range is hence
1878982656+65535=1879048191.)
Systemd has compile-time default for these boundaries. Using those defaults is
recommended. It will nevertheless query at runtime, when
compiled with and that file is present.
Support for this is considered only a compatibility feature and should not be
used except when upgrading systems which were created with different defaults.
Как использовать UID в программировании?
UID (идентификатор уникальности) устройства может быть полезен в программировании для ряда задач, связанных с идентификацией и управлением устройствами.
Одна из наиболее распространенных задач, которые можно решить с помощью UID, — это обеспечение безопасности приложений. Например, приложение может сохранять некоторые самые важные данные на сервере, вне устройства пользователя. В таком случае, программа будет требовать UID, прежде чем позволить пользователю получить доступ к этим данным. Это позволяет предотвратить несанкционированный доступ к критическим данным.
Еще один пример использования UID — это управление доступом к определенному функционалу устройства. Например, если на устройстве есть определенное приложение, которое должно иметь доступ к геопозиционированию, то это приложение может запросить UID для этой функции и использовать ее при необходимости. Это помогает избежать многих проблем с безопасностью и конфиденциальностью данных.
Наконец, UID может использоваться для аутентификации устройства в системе. Это помогает обеспечить дополнительный уровень безопасности, связанный с доступом к критическим или личной информации на сервере.
В целом, использование UID в программировании может обеспечить много преимуществ, связанных с безопасностью данных и управлением устройствами. Однако необходимо помнить, что UID должен храниться в надежном месте, и не должен быть доступен для несанкционированного использования. Кроме того, необходимо разделять доступ к UID в соответствии со строгими политиками безопасности, чтобы уменьшить риски связанные с использованием UID в приложениях.
Создание и удаление пользователей
Для того, чтобы создать нового пользователя в системе можно воспользоваться двумя утилитами:
- useradd — не интерактивная утилита;
- adduser — интерактивная утилита;
Любой из этих команд нужно передать имя пользователя, но useradd не создаст пользователю домашний каталог и не придумает пароль если не использовать дополнительные опции команды. Зато создаст одноименную группу пользователя и включит этого пользователя в неё. Создавать пользователей в системе может только root:
root@deb:~# useradd testuser root@deb:~# su - testuser su: warning: cannot change directory to /home/testuser: Нет такого файла или каталога $ id uid=1001(testuser) gid=1001(testuser) группы=1001(testuser) $ pwd /root $ exit root@deb:~#
У этой утилиты есть некоторые опции:
- -m — создать домашний каталог пользователю;
- -p <пароль> — здесь нужно ввести хешированный пароль, что не всегда удобно, поэтому не стоит использовать эту опцию;
- -s <путь_к_оболочке> — указать командную оболочку используемую по умолчанию для пользователя (сейчас мы работает в оболочке bash, путь к ней — /bin/bash);
Давайте теперь удалим пользователя testuser и создадим его по новой с изученными опциями. Удаляется пользователь командой deluser.
root@deb:~# userdel testuser root@deb:~# useradd -m -s /bin/bash testuser root@deb:~# su - testuser testuser@deb:~$ pwd /home/testuser testuser@deb:~$ id uid=1001(testuser) gid=1001(testuser) группы=1001(testuser) testuser@deb:~$ exit выход root@deb:~#
При удалении пользователя командой userdel, с помощью дополнительных опций можно:
- -f — завершить все процессы пользователя и удалить насильно, даже если пользователь сейчас работает в системе;
- -r — удалить домашний каталог пользователя;
Теперь давайте удалим пользователя testuser и попробуем создать его интерактивной утилитой adduser:
root@deb:~# userdel -f -r testuser
userdel: почтовый ящик testuser (/var/mail/testuser) не найден
root@deb:~# adduser testuser
Добавляется пользователь «testuser» ...
Добавляется новая группа «testuser» (1001) ...
Добавляется новый пользователь «testuser» (1001) в группу «testuser» ...
Создаётся домашний каталог «/home/testuser» ...
Копирование файлов из «/etc/skel» ...
Новый пароль:
Повторите ввод нового пароля:
passwd: пароль успешно обновлён
Изменение информации о пользователе testuser
Введите новое значение или нажмите ENTER для выбора значения по умолчанию
Полное имя []:
Номер комнаты []:
Рабочий телефон []:
Домашний телефон []:
Другое []:
Данная информация корректна? [Y/n] y
root@deb:~# su - testuser
testuser@deb:~$ pwd
/home/testuser
testuser@deb:~$ id
uid=1001(testuser) gid=1001(testuser) группы=1001(testuser)
testuser@deb:~$ exit
выход
root@deb:~#
При использовании adduser, утилита у нас запросит пароль для нового пользователя, создаст одноименную группу для пользователя, также мы можем ввести дополнительную информацию о пользователе: полное имя, номер комнаты, рабочий телефон, домашний телефон.
Эта утилита тоже имеет опции, благодаря которым можно:
- —no-create-home — не создавать домашний каталог пользователю;
- —shell <Оболочка> — задать оболочку для пользователя, по умолчанию задается оболочка bash;
Зачем же созданы две утилиты для создания пользователей? Я бы рекомендовал использовать adduser при ручном создании пользователя и useradd при создании пользователя из скрипта, так как useradd в процессе работы не задает вопросы, а создает пользователя используя опции.
Для удаления пользователей тоже можно использовать две утилиты:
- userdel;
- deluser.
Они различаются только опциями.
userdel:
- -r — удалить домашний каталог пользователя;
- -f — завершить все процессы пользователя и удалить насильно, даже если пользователь сейчас работает в системе;
deluser:
- —remove-home — удалить домашний каталог пользователя;
- —force — завершить все процессы пользователя и удалить насильно, даже если пользователь сейчас работает в системе;
Мне опции первой команды запомнить легче, да и запись получается короче, поэтому я использую userdel.
Оглавление:
Определение — Что означает универсальный уникальный идентификатор (UUID)?
Универсальный уникальный идентификатор (UUID) — это 128-битное число, которое идентифицирует уникальные интернет-объекты или данные. UUID генерируется алгоритмом со значениями, которые основаны на сетевом адресе машины.
UUID используются многими компаниями-разработчиками программного обеспечения, такими как Microsoft и Apple, и широко используются в качестве компонентов глобально уникальных идентификаторов Microsoft (GUID). Другое использование UUID включает файловую систему ext2 / ext3 в Linux.
Techopedia объясняет универсальный уникальный идентификатор (UUID)
UUID был создан в сетевой вычислительной системе (NCS), которая впоследствии стала частью распределенной вычислительной среды (DCE), стандартизированной Open Software Foundation (OSF).
UUID обычно обозначается 32 шестнадцатеричными цифрами, отображаемыми в пяти группах символов, разделенных дефисами. Например, UUID может выглядеть следующим образом: f81d4fae-7dec-11d0-a765-00a0c91e6bf6.


Различные механизмы используются для генерации UUID для определения и сравнения уровней уникальности UUID. В зависимости от типа используемого механизма сгенерированный UUID будет либо полностью, либо практически отличаться от других сгенерированных UUID. UUID состоят из комбинированных компонентов; следовательно, некоторая уникальность всегда присутствует в любом сгенерированном UUID.
Гарантированный уникальный идентификатор включает в себя ссылку на сетевой адрес хоста, генерирующего UUID, метку времени и произвольный компонент. Поскольку сетевые адреса для каждого компьютера различаются, отметка времени также отличается для каждого сгенерированного UUID. Таким образом, две разные хост-машины демонстрируют достаточные уровни уникальности. Произвольно созданный произвольный компонент добавлен для повышения безопасности.
UUID также являются частью структуры данных Tmodel, которая является типом службы в реестре универсального описания и интеграции (UDDI), используемой для обнаружения веб-службы.
Добавление пользователей в группу
Продолжим изучение темы «Группы и пользователи в Linux». Теперь рассмотрим процесс добавление в группу пользователей. Но для начала разберемся с первичными и дополнительными группами. Как я показывал раньше, при создании пользователя обычно создается одноименная группа это первичная группа пользователя. Первичная группа используется, например, при создании файла.
Например, если пользователь Linux «Вася» имеет первичную группу «Вася» и какие-то дополнительные группы, и он создал файл, то к файлу будут иметь доступ все пользователи которые входят в группу «Вася». Но одна из дополнительных групп у «Васи» — это группа «Разработчики», и у группы «Разработчики» не будет доступа к файлу, так как файл взял права от первичной группы «Вася», а не от дополнительной «Разработчики» . Это просто пример поведения Linux, с системой прав разберемся позже.
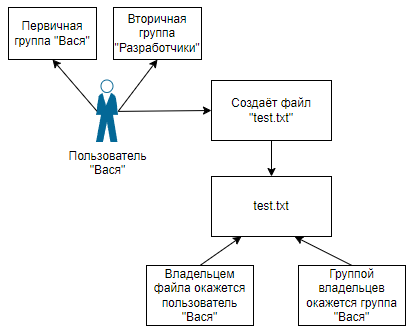 Группы и пользователи в Linux
Группы и пользователи в Linux
В одном из примеров выше я показывал вывод команды id для пользователя alex:
alex@deb:~$ id uid=1000(alex) gid=1000(alex) группы=1000(alex),24(cdrom),25(floppy),29(audio),30(dip),44(video),46(plugdev),109(netdev)
Тут первичная группа alex, а дополнительные все остальные.
Чтобы пользователю добавить дополнительную группу можно воспользоваться командой usermod -aG,
- -a — добавляет к текущим группам пользователя дополнительные. Без этой опции группы заменяются на новые, а с этой опцией к старым группам добавляются новые;
- -G — указывает, что работать будем с дополнительными группами а не с первичной.
alex@deb:~$ su - Пароль: root@deb:~# usermod -aG testgroup alex root@deb:~# id alex uid=1000(alex) gid=1000(alex) группы=1000(alex),24(cdrom),25(floppy),29(audio),30(dip),44(video),46(plugdev),109(netdev),1002(testgroup) root@deb:~#
Как видим alex добавился в группу testgroup.
Утилитой usermod нельзя удалять дополнительные группы, можно только не используя опцию -a, написать список групп в которые должен будет входить данный пользователь, не указав ту группу, из которой вы хотите удалить пользователя. Например мы хотим удалить alex из testgroup:
root@ubu:~# usermod -G adm,cdrom,sudo,dip,plugdev,lxd alex root@ubu:~# id alex uid=1000(alex) gid=1000(alex) groups=1000(alex),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),116(lxd) root@deb:~# usermod -G cdrom,floppy,audio,dip,video,plugdev,netdev alex root@deb:~# id alex uid=1000(alex) gid=1000(alex) группы=1000(alex),24(cdrom),25(floppy),29(audio),30(dip),44(video),46(plugdev),109(netdev)
Если мы хотим поменять пользователю первичную группу, то нужно использовать опцию -g:
root@deb:~# usermod -g testgroup alex root@deb:~# id alex uid=1000(alex) gid=1002(testgroup) группы=1002(testgroup),24(cdrom),25(floppy),29(audio),30(dip),44(video),46(plugdev),109(netdev)
И вернем все как было:
root@deb:~# usermod -g alex alex
Еще один способ добавить пользователя в дополнительную группу (и наверное более запоминающийся) это использовать утилиту adduser, при этом утилите вначале передается имя пользователя, затем группы:
root@deb:~# adduser alex testgroup Добавляется пользователь «alex» в группу «testgroup» ... Добавление пользователя alex в группу testgroup Готово.
Удалить пользователя из группы можно командой deluser:
root@deb:~# deluser alex testgroup Удаляется пользователь «alex» из группы «testgroup» ... Готово.
И так, для добавления или удаления пользователя в дополнительную группу я бы рекомендовал использовать команды adduser и deluser. А для изменения первичной группы команду usermod -g.