Как переводится такое сообщение?
При работе с программой пользователи могут получить сообщение «You are being rate limited». Фраза означает, что произошла ошибка в приложении, которая требует исправления. Если рассматривать буквальный перевод, то выражение «You are being rate limited» можно перевести, что вы ограничены в скорости действия. Если рассматривать смысл ситуацию, пользователь не может производить необходимое действие в программе Дискорд. Ошибка может выйти при нарушении работы приложения.
Если вы ограничены в скорости действия, это означает, что вы пробовали это действие много раз за короткий промежуток времени, поэтому вам нужно будет дождаться истечения этого таймера ограничения скорости, прежде чем разрешат повторить попытку. К сожалению, нет точного определения для периода тайм-аута. Как правило, ошибка не длится большой период времени, но при нарушении работы на платформе, ошибка может затянуться, и мешать стандартному варианту выполнения работы в программе Дискорд. Например, при прохождении процедуры регистрации, пользователи могут постараться ввести предложенный код несколько раз, и поэтому программа выдаст ошибку. Сложность может возникнуть и по идентичной причине.
Для решения проблемы можно воспользоваться универсальными советами. Пользователи могут не производить действий, поскольку ошибка может исчезнуть без манипуляций со стороны пользователя. Ошибка возникает у начинающих пользователей, или опытных юзеров в программе Дискорд.
Load testing
It’s common for users to prepare for a major sales event by load testing their systems, with the Stripe API running in test mode as part of it. We generally discourage this practice because API limits are lower in test mode, so the load test is likely to hit limits that it wouldn’t hit in production. Test mode is also not a perfect stand-in for live API calls, and that can be somewhat misleading. For example, creating a charge in live mode sends a request to a payment gateway and that request is mocked in test mode, resulting in significantly different latency profiles.
As an alternative, we recommend building integrations so that they have a configurable system for mocking out requests to the Stripe API, which you can enable for load tests. For realistic results, they should simulate latency by sleeping for a time that you determine by sampling the durations of real live mode Stripe API calls, as seen from the perspective of the integration.
Ограничение скорости для доступа к ресурсам
Ограничение скорости для доступа к ресурсам (rate limiting) является одним из методов контроля и ограничения использования интернет-ресурсов для определенного пользователя или приложения. Целью этого механизма является предотвращение перегрузок и снижение нагрузки на серверы, а также обеспечение равномерного распределения ресурсов между всеми пользователями.
Ограничение скорости может быть применено как на уровне сетевого соединения, так и на уровне сервера. В первом случае ограничение скорости будет применяться к всем сетевым пакетам, проходящим через соединение, а во втором случае — к запросам, поступающим на сервер.
Существуют различные методы ограничения скорости доступа к ресурсам. Наиболее распространенными являются:
- Ограничение по времени — в рамках определенного временного интервала устанавливается максимальное количество запросов или пакетов данных, которые могут быть обработаны;
- Ограничение по частоте — устанавливается максимальное количество запросов или пакетов данных, которые могут быть обработаны в течение заданного периода времени (например, в секунду или минуту);
- Ограничение по объему данных — устанавливается максимальный объем данных, который может быть передан или получен за определенный период времени;
- Ограничение по типу запросов — определенные типы запросов могут быть ограничены или заблокированы полностью;
Ограничение скорости может быть полезным при защите ресурсов от злоумышленников, предотвращении перегрузок или предоставлении ограниченного доступа для определенных пользователей или приложений.
В рамках данной статьи рассмотрены основные аспекты ограничения скорости доступа к ресурсам и его влияние на работу в интернете. Ознакомившись с этой информацией, пользователи и разработчики могут более эффективно использовать интернет-ресурсы и обращаться к ним в соответствии с заданными ограничениями.
Другие способы увеличения rate limit для GPT чат-бота
Если вам не хватает базового лимита запросов для работы с GPT чат-ботом, существуют несколько способов увеличить его.
1. Подключение к платной версии
Одним из самых простых способов увеличить rate limit является переход на платную версию GPT API с более высоким лимитом запросов. Платные варианты предоставляют больше возможностей и гибкость в использовании сервиса.
2. Оптимизация запросов
Другим способом увеличить rate limit является оптимизация ваших запросов к GPT API. Попробуйте уменьшить количество запросов, необходимых для выполнения задачи, путем объединения нескольких запросов в один или использования батчей запросов.
3. Кэширование ответов
Если ваше приложение делает множество повторяющихся запросов к GPT API, вы можете реализовать кэширование ответов. При получении ответа от API вы можете сохранить его в локальном кэше и при следующем запросе проверить, есть ли уже сохраненный ответ. Это может существенно снизить количество запросов к API и увеличить rate limit.
4. Использование разных аккаунтов
Если вы работаете в команде или у вас есть несколько аккаунтов, вы можете использовать разные аккаунты для выполнения запросов. Каждый аккаунт будет иметь собственный лимит запросов, поэтому, используя несколько аккаунтов одновременно, вы можете увеличить общий лимит.
5. Обращение к службе поддержки
Если ни один из вышеперечисленных способов не подходит, вы можете связаться со службой поддержки GPT API и обсудить с ними возможность увеличения вашего rate limit. Они могут предложить варианты, которые подходят под ваши конкретные требования и обстоятельства.
Используя эти способы, вы можете увеличить rate limit для вашего GPT чат-бота и успешно выполнять задачи, требующие большего количества запросов к API.
API read request allocations
Stripe provides access to its read (GET) API requests to facilitate reasonable lookup activity related to payment integrations. To maximize quality of service for all users, Stripe provides the following allocations for read requests based on transaction count:
- Read API requests shouldn’t exceed an average ratio of 500 requests per transaction for an account. For example, if an account processes 100 transactions in a 30-day period, they shouldn’t exceed 50,000 read API requests during that same period.
- When using Connect, a platform and its connected accounts have distinct read API allowances:
- Each connected account has their own allocation for requests they initiate (500 requests per transaction).
- Connect platforms use a separate allocation to make read requests on behalf of their connected accounts using either their secret API key or OAuth access tokens. This allocation is also 500 requests per transaction based on the aggregate transaction count across its connected accounts.
- Ratios are measured on a rolling 30-day basis.
- Every account, regardless of transaction count, has a minimum allocation of 10,000 read requests per month.
- Write API requests have no allocation limit.
Calls to the following API endpoints are excluded from the above allocation limits:
- Data products
- Reporting products
- Tax products
To reduce your API request volume, consider using Stripe Data Pipeline for a complete export of API data to your local database or provider.
Filter requests to limit paginated calls
Some list endpoints return multiple pages of results and might require multiple requests to return the full set of API objects for a list operation. Apply filters when possible to narrow your list results.
Types Of Rate Limiting
Tyk offers the following rate limiting algorithms to protect your APIs:
- Distributed Rate Limiter. Most performant, not 100% accurate. Recommended for most use cases. Implements the .
- Redis Rate Limiter. Less performant, 100% perfect accuracy. Implements the .
- Leaky Bucket Rate Limiter. Implements delays on requests so they can be processed at the configured rate. Implements the .
Distributed Rate Limiter (DRL)
This is the default rate limiter in Tyk. It is the most performant but has a trade-off that the limit applied is approximate, not exact. To use a less performant, exact rate limiter, review the Redis rate limiter below.
The Distributed Rate Limiter will be used automatically unless one of the other rate limit algorithms are explicitly enabled via configuration.
With the DRL, the configured rate limit is split (distributed) evenly across all the gateways in the cluster (a cluster of gateway shares the same Redis). These gateways store the running rate in memory and return when their share is used up.
This relies on having a fair load balancer since it assumes a well distributed load between all the gateways.
The DRL implements a token bucket algorithm. In this case if the request rate is higher than the rate limit it will attempt to let through requests at the specified rate limit. It’s important to note that this is the only rate limit method that uses this algorithm and that it will yield approximate results.

Redis Rate Limiter
This uses Redis to track and limit the rate of incoming API calls. An important behaviour of this method is that it blocks access to the API when the rate exceeds the rate limit and does not let further API calls through until the rate drops below the specified rate limit. For example, if the rate limit is 3000/minute the call rate would have to be reduced below 3000 for a whole minute before the HTTP 429 responses stop.
For example, you can slow your connection throughput to regain entry into your rate limit. This is more of a “throttle” than a “block”.
This algorithm can be managed using the following configuration option .
Redis Sentinel Rate Limiter
As explained above, when using the Redis rate limiter, when a throttling action is triggered, requests are required to cool-down for the period of the rate limit.
The default behaviour with the Redis rate limiter is that the rate-limit calculations are performed on-thread.
The optional Redis Sentinel rate limiter delivers a smoother performance curve as rate-limit calculations happen off-thread, with a stricter time-out based cool-down for clients.
This option can be enabled using the following configuration option .
Performance
The Redis limiter is indeed slower than the DRL, but that performance can be improved by enabling the . This leverages Redis Pipelining to enhance the performance of the Redis operations. Here are the for more information.
DRL Threshold
Optionally, you can use both rate limit options simultaneously. This is suitable for hard-syncing rate limits for lower thresholds, ie for more expensive APIs, and using the more performant Rate Limiter for the higher traffic APIs.
Tyk switches between these two modes using the . If the rate limit is more than the drl_threshold (per gateway) then the DRL is used. If it’s below the DRL threshold the redis rate limiter is used.
Read more
The Redis rate limiter provides 100% accuracy, however instead of using the token bucket algorithm it uses the sliding window log algorithm. This means that if there is a user who abuses the rate limit, this user’s requests will be limited until they start respecting the rate limit. In other words, requests that return 429 will count towards their rate limit counter.
Leaky bucket rate limiter
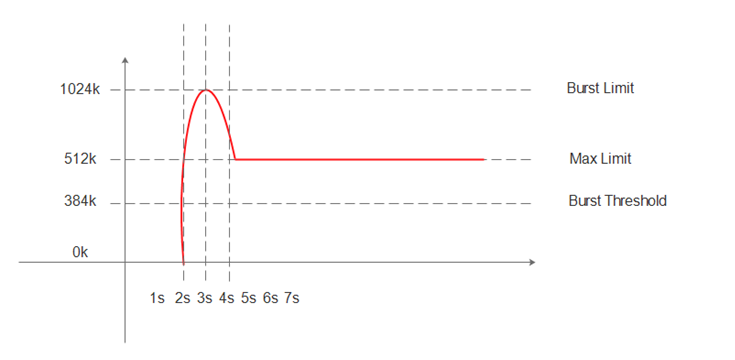
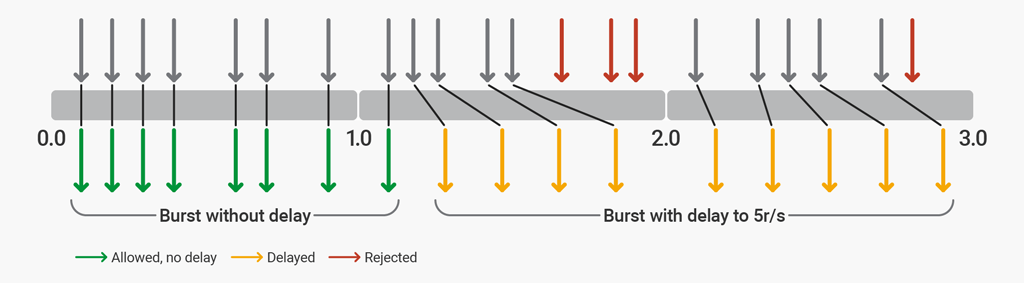
Leaky bucket rate limiting will add delays to incoming requests to control the outgoing request rate to what is configured. It handles traffic bursts and smooths them out to the configured rate.
This option can be enabled using the following configuration option .
Impact: the gateway needs to queue the requests up to the defined limit and that comes with some performance penalties. The responses add latency if the request rate goes beyond the defined limits.
Как Rate Limiting может повлиять на пользовательский опыт?
Rate Limiting – это техника, которая используется для ограничения количества запросов, которые могут быть выполнены пользователем или клиентским приложением за определенный промежуток времени. В реальности это может повлиять на пользовательский опыт, обязательно приведу примеры, чтобы было понятнее.
1. Задержка ответа:
Когда веб-сервер встречает ограничение скорости, он может задерживать ответ на некоторое время, прежде чем отправить его обратно клиенту. Если задержка слишком большая, это может привести к неудовлетворительному пользовательскому опыту. Пользователи могут столкнуться с долгими интервалами ожидания между запросами и ответами, что может вызвать разочарование и негативное впечатление о сайте.
2. Ошибка «Too Many Requests»:
Когда пользователь или клиентское приложение превышают установленные ограничения скорости, сервер может вернуть ошибку «Too Many Requests» (Слишком много запросов). Эта ошибка сообщает клиенту, что он выполнил слишком много запросов за определенный период времени и должен подождать, прежде чем выполнить дополнительные запросы. Такие ограничения могут вызвать раздражение и недовольство пользователей, особенно если они не осознают, что это связано с защитой сервера.
3. Увеличенное время загрузки страниц:
Если веб-сайт имеет установленное ограничение скорости и пользователь или клиентское приложение превышают это ограничение, сервер может использовать механизмы замедления загрузки страницы. Это может привести к увеличению времени, требуемого для загрузки каждого элемента страницы, таких как изображения, стили, скрипты и другие. Увеличенное время загрузки страницы может вызывать нетерпение у пользователей и негативно повлиять на их общее впечатление от сайта.
4. Ограничения функционала:
Rate Limiting также может применяться для ограничения функционала сайта. Например, если есть ограничение на количество запросов, которые могут быть выполнены для выполнения определенного действия (например, отправка сообщений, загрузка файлов), то пользователи могут столкнуться с необходимостью ожидания или неспособностью выполнить нужное действие из-за ограничений.
В целом, Rate Limiting является важной мерой для защиты серверов от злоумышленников или избыточного использования, но его неправильное настройка или применение может негативно повлиять на пользовательский опыт. Важно находить правильный баланс между защитой и комфортом пользователей при использовании данной техники
Overview
I’ve been working on a Rails side-project where I need to frequently poll an external API for data in response to user activity. The polling takes place in the background via Sidekiq jobs.
The challenge is that this external API is notoriously strict about enforcing a rate limit: if the API is called too frequently, it will start failing with HTTP 400 errors. In the past I have tried solving this using the sidekiq-throttled gem. It sometimes works, but maintenance of the gem is spotty, and new Sidekiq releases often cause the gem to break.
I’ve now landed on a more robust approach using a new official feature of Sidekiq, paired with a gem from Shopify. I’ll walk you through the following solution in this post:
- How to use a Sidekiq capsule to limit concurrency, so that rate-limited jobs are constrained to a single thread.
- How to enforce a rate limit with the ruby-limiter gem, so that API calls don’t exceed a certain number per minute.
Have you also implemented something like this using a different approach? Let me know!
Rate limiting at the ingress gateway
We can configure the rate limiter at the ingress gateway as well. We can use the same configuration as before, but we need to apply it to the workload instead. Because there’s a differentiation between the configuration for sidecars and gateways, we need to use a different context in the EnvoyFilter resource ().
Everything else stays the same:
To test this configuration, we need to expose the workload through the ingress gateway. We can do that by creating a and a resource:
Let’s apply this configuration first and try it out:
As you can see, the request was successful. Now let’s apply the rate limiter configuration and try again:
Once the rate limiter kicks in, we’ll see the same responses as before:
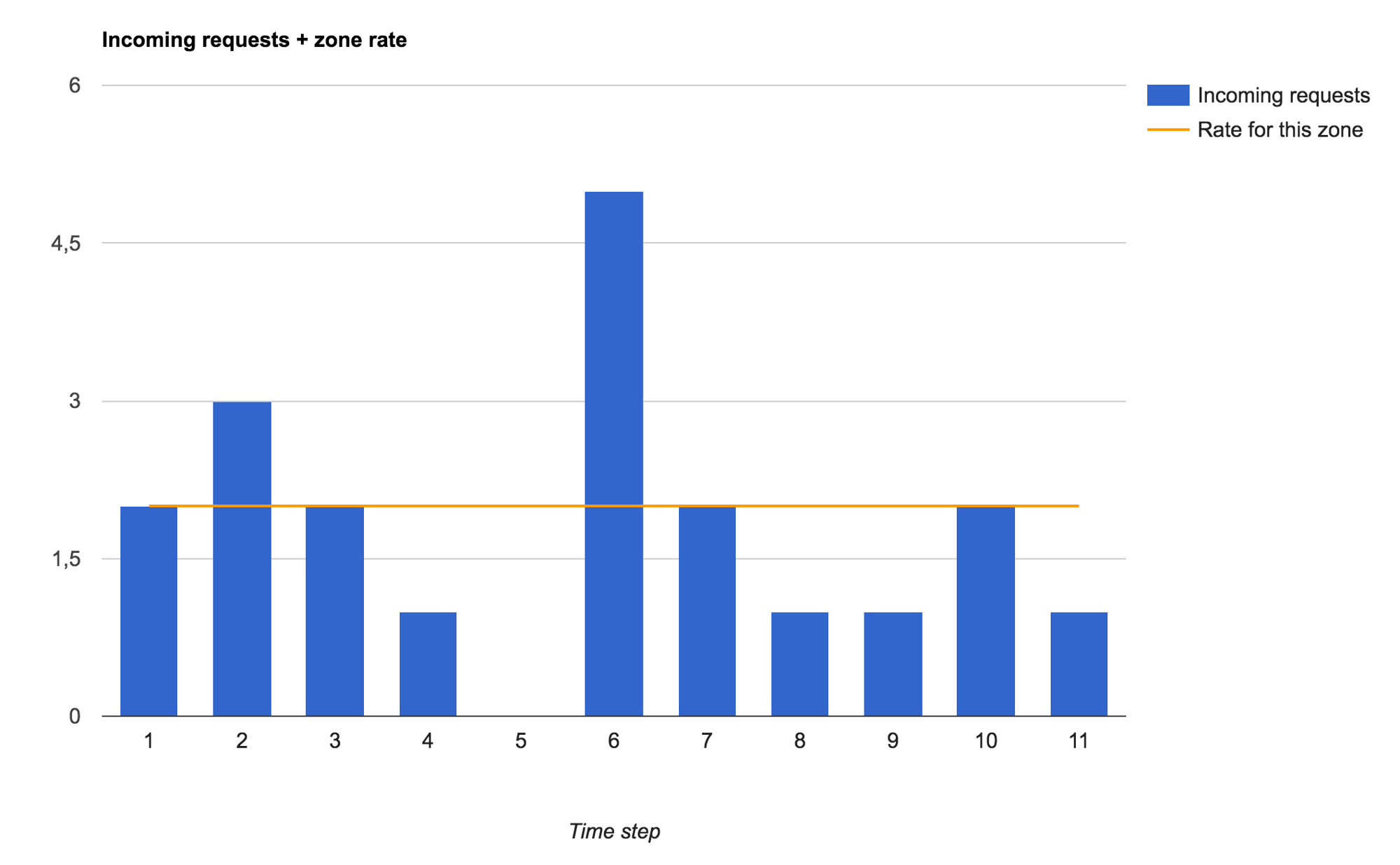
If we open Prometheus we can now visualize the rate limiters for both the httpbin workload and the ingress gateway. We can use the same metric name, but specify the app name as an attribute.
Prometheus and rate limiter metrics
We can take this a step further and also create a dashboard for the rate limiter metrics in Grafana.
Grafana and rate limiter metrics
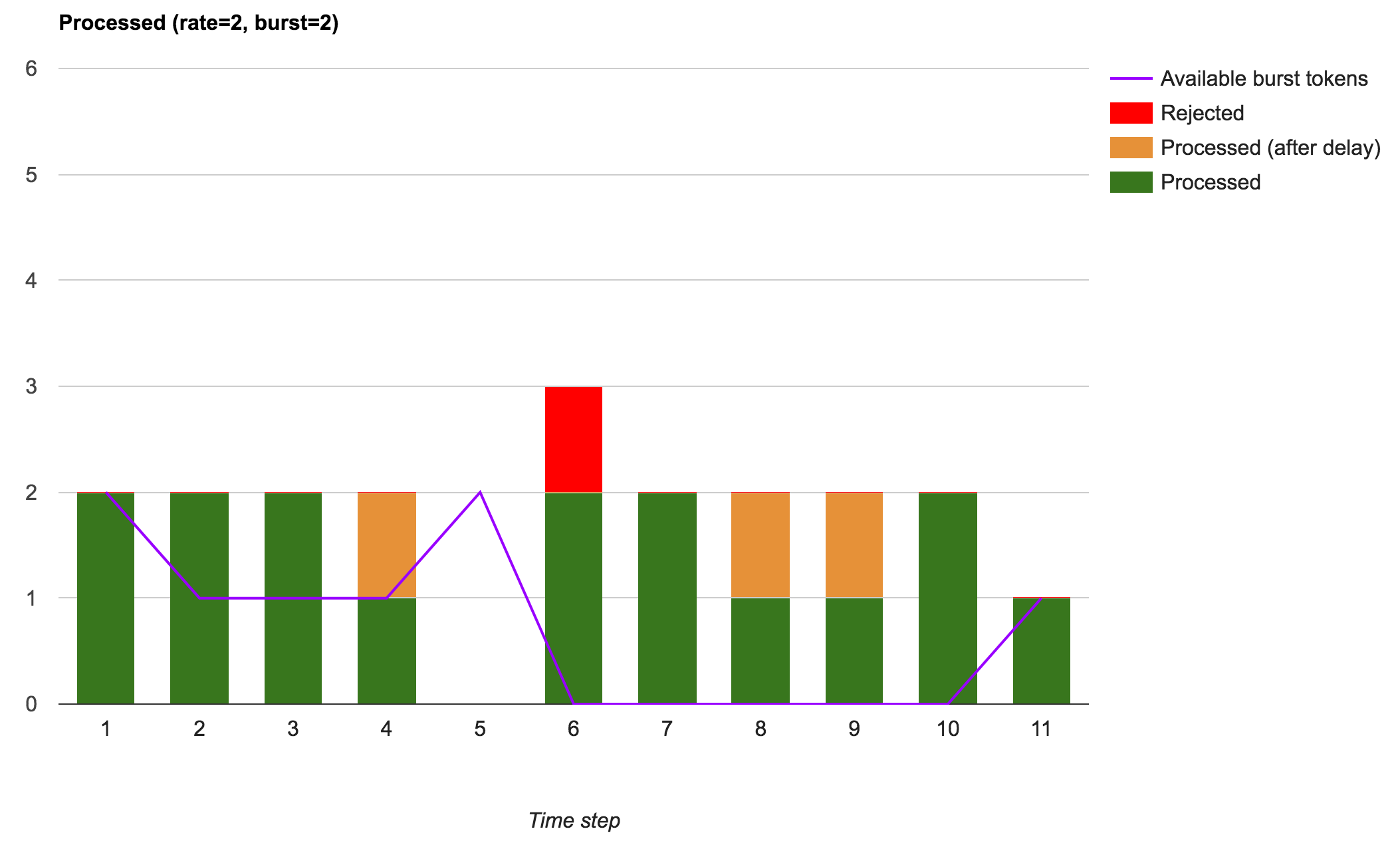
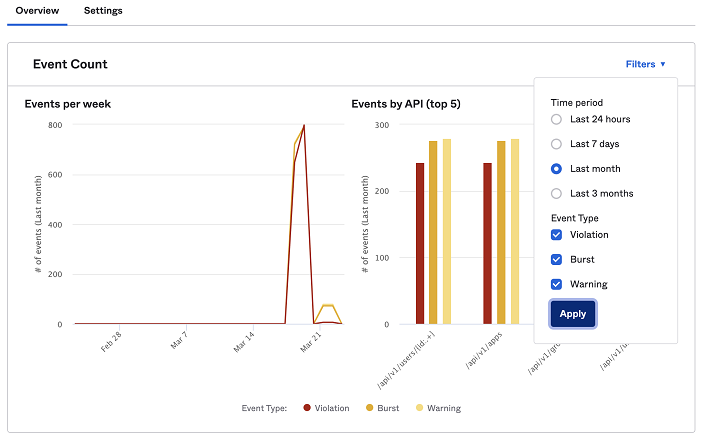
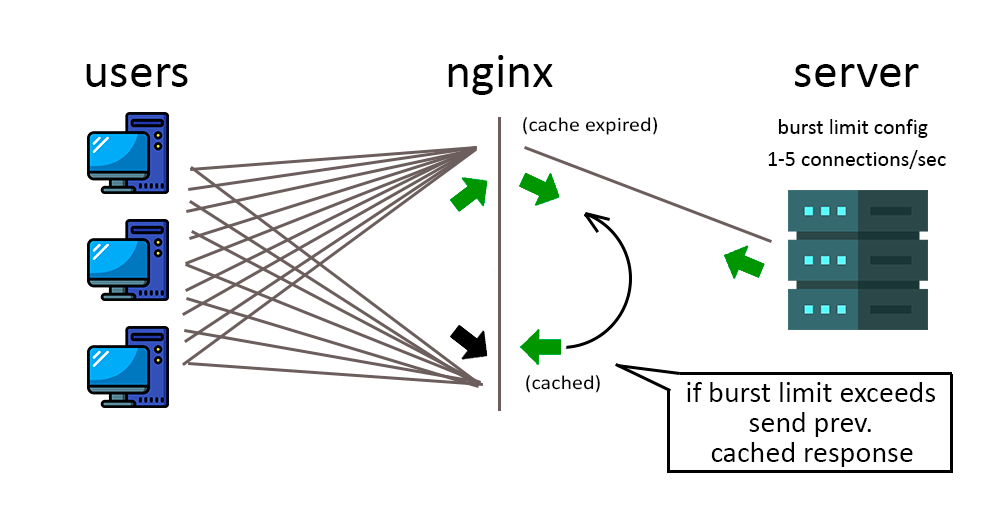
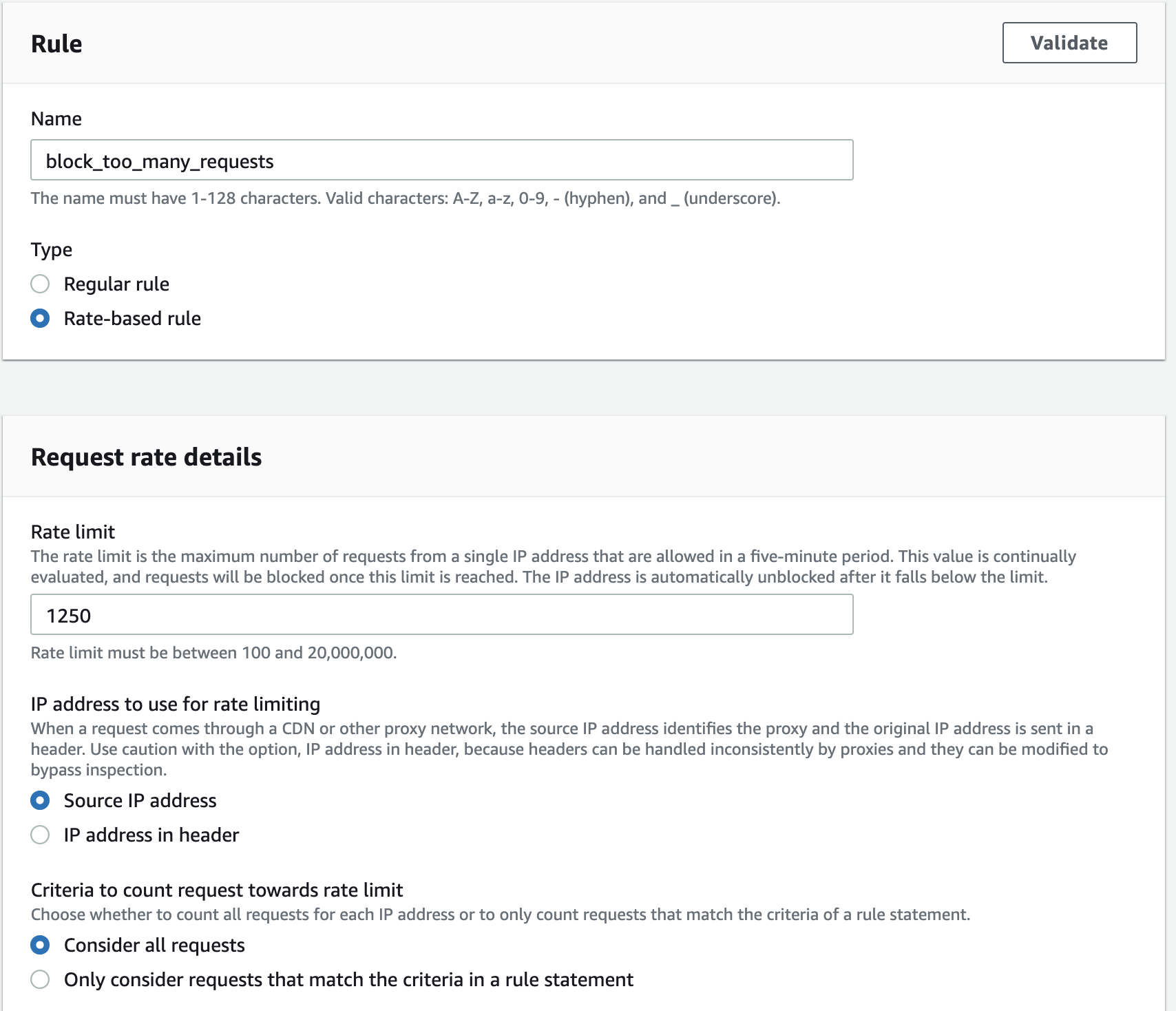
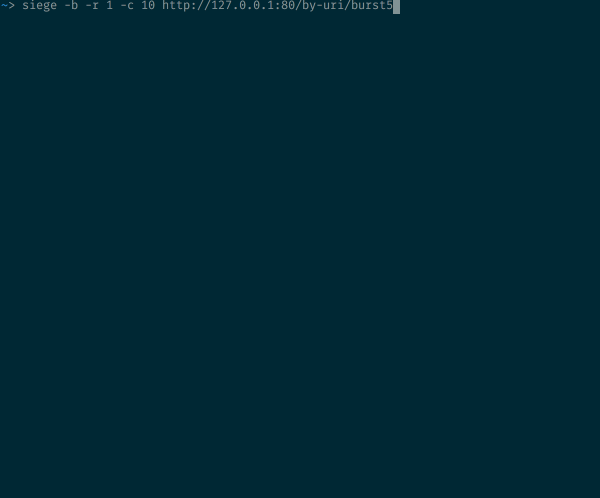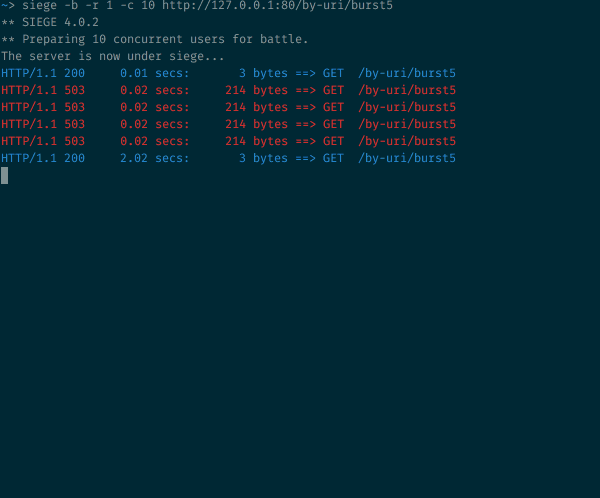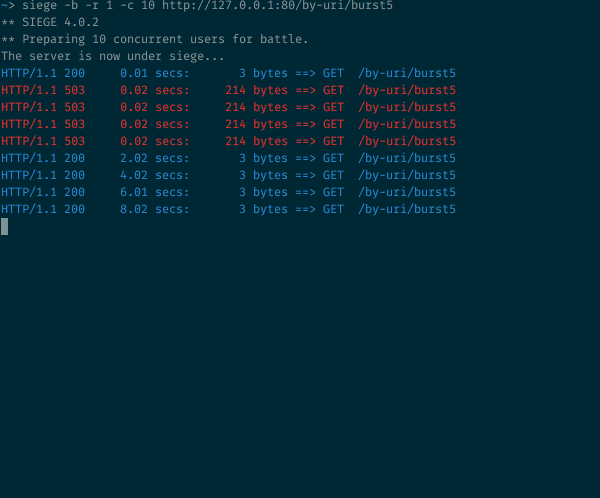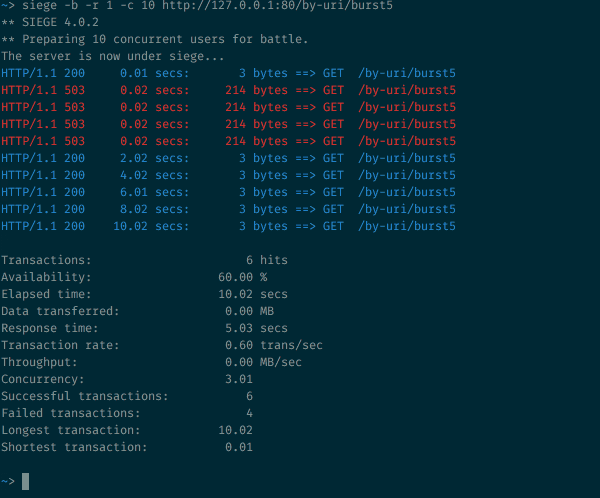
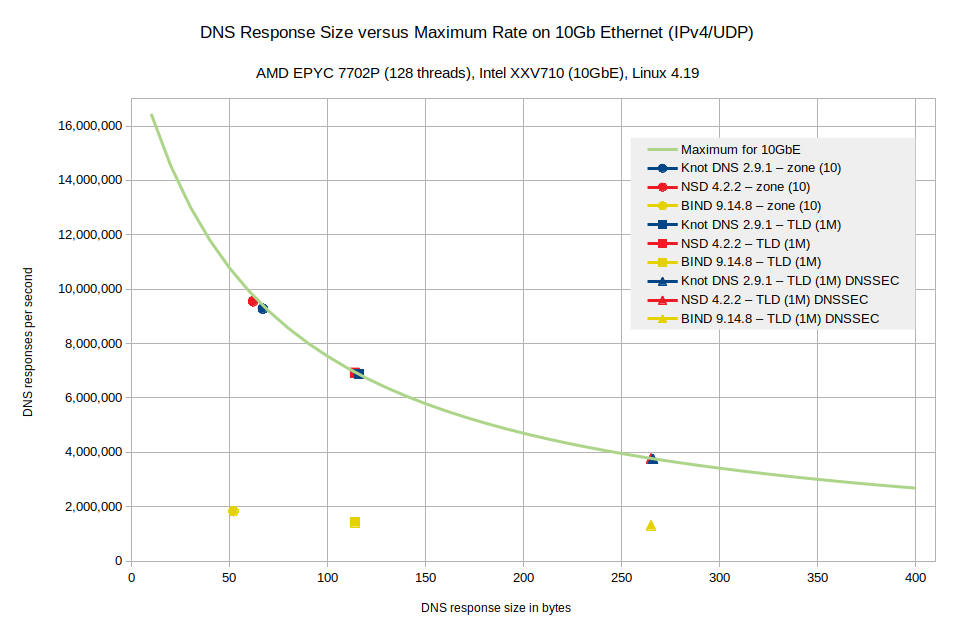
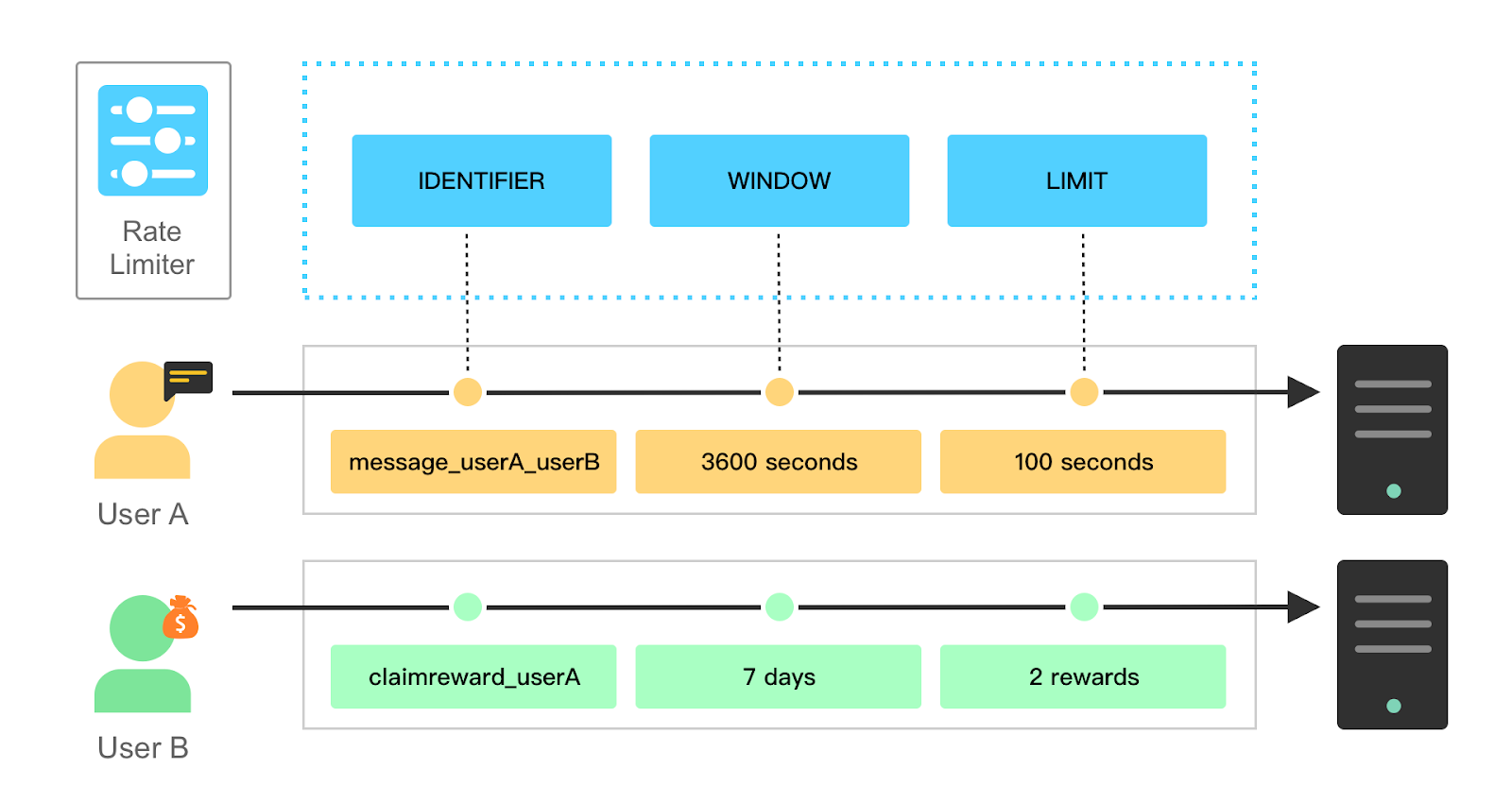
Rate limited — работа с ограничением скорости
Rate Limiting, или ограничение скорости, используется для управления количеством запросов, которые клиент может отправить к определенному сервису или API в заданный промежуток времени. Это мера безопасности, которая помогает предотвратить перегрузку системы, запрашиваемой информацией, или злоупотребление сервисом.
Когда клиент выполняет слишком много запросов в короткий промежуток времени, API или сервис может отклонить последующие запросы или предоставить их с задержкой. Такие ограничения позволяют балансировать нагрузку на систему и обеспечивать более стабильную работу сервиса для всех пользователей.
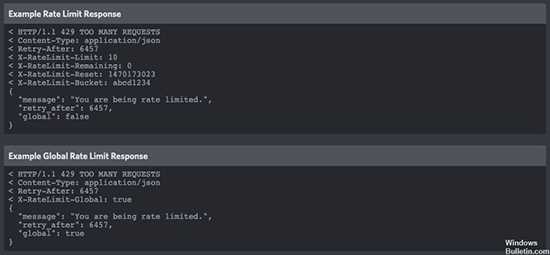
Если ваш запрос был ограничен ограничением скорости (rate limited), API может в ответ на ваш запрос отправить код состояния HTTP 429 (Too Many Requests) или другой код, указывающий на ограничение скорости.
Для работы с ограничением скорости, следуйте следующим рекомендациям:
-
Ознакомьтесь с документацией API. В документации API должны быть указаны подробности о том, какие ограничения скорости применяются и какие значения они имеют.
-
Учитывайте промежутки времени. API может иметь разные промежутки времени, в течение которых ограничения скорости применяются. Некоторые API могут ограничивать число запросов каждую минуту, каждый час или каждый день.
-
Используйте систему обратной связи. Если ваш запрос был отклонен из-за ограничения скорости, API может возвращать заголовок ответа, содержащий информацию о текущих ограничениях скорости и время, через которое можно отправить следующий запрос.
-
Рассмотрите кэширование. Если вы делаете множество одинаковых запросов, можно использовать кэширование. Кэширование позволяет сохранить ответ от сервера и повторно использовать его вместо повторной отправки запроса.
Работа с ограничением скорости может быть важной частью разработки приложений, использующих внешние API. Учитывайте ограничения скорости, указанные в документации API, и планируйте свои запросы таким образом, чтобы не превышать лимиты и получать ресурсы, необходимые для вашего приложения
Blocking high volume traffic
In order to protect ourselves from online attacks caused by misconfigured API integrations, users abusing our system by not respecting our rate limits and keeping up the high volume of traffic despite getting the response code, will also get the response code. When getting the response code, the answer will be an HTML error page with the message «This error is produced by Cloudflare. See troubleshooting guide here.», informing the user that one’s access has been denied:
Please note that this improvement will not impact the vast majority of users, even if our API is heavily used. If this impacts you, please review your integration and remove any misconfiguration that might lead you to be blocked.
How to avoid being rate limited
If you’re reaching the rate limit, options to improve performance include restructuring the integration architecture, using Webhooks, and/or upgrading to Advanced, Professional or Enterprise plan.
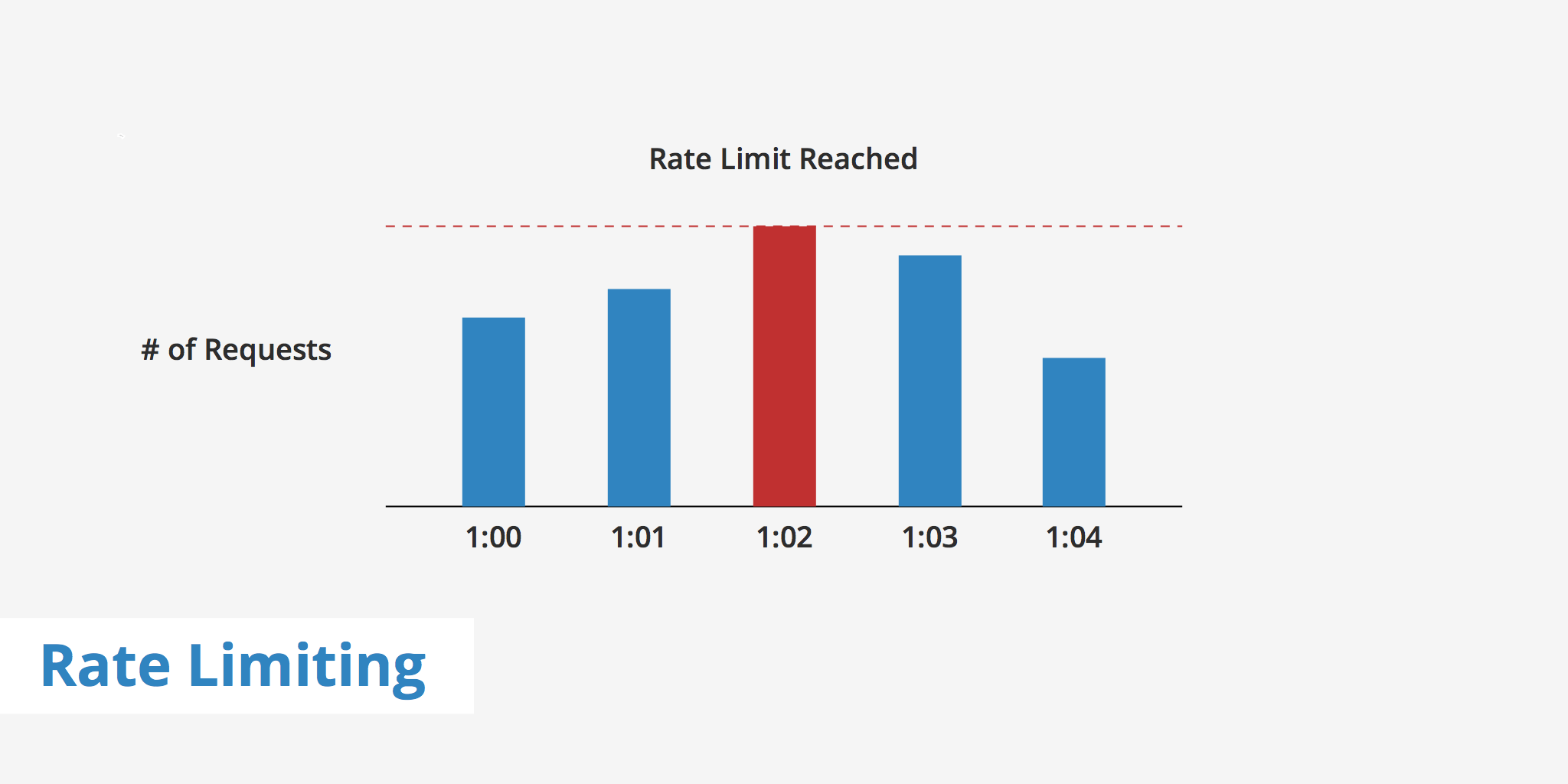
How Does Rate Limiting work?
Rate limiting works by controlling the rate at which requests are made to a system or service. It sets a limit on the number of requests that can be made within a specific time frame, typically measured in seconds, minutes, or hours. When the limit is reached, the system or service may either delay or reject further requests until the next time window begins.
Rate limiting can be implemented in several ways, including:
Token bucket algorithm — This algorithm involves adding tokens to a bucket at a fixed rate. When a request is made, a token is removed from the bucket. If no tokens are available, the request is delayed or rejected.
Leaky bucket algorithm — This algorithm involves filling a bucket at a fixed rate and allowing requests to drain from the bucket at a fixed rate. If the bucket overflows, the requests are delayed or rejected.
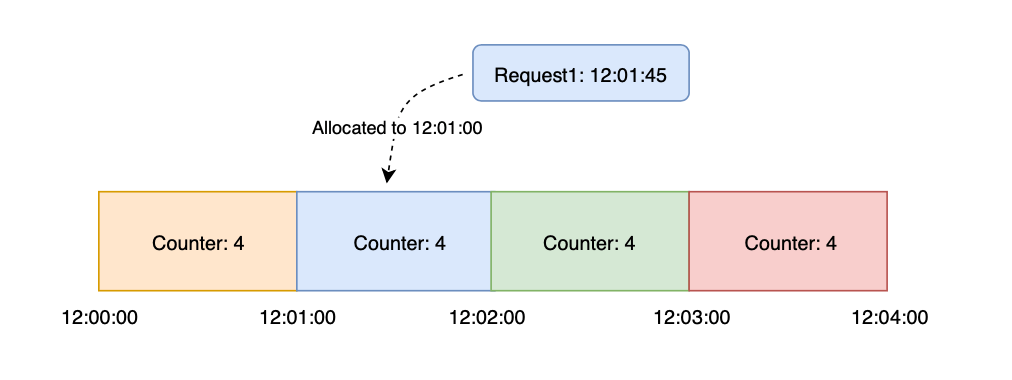
Rolling window algorithm — This algorithm involves counting the number of requests made within a sliding time window, typically measured in seconds or minutes. The window slides forward with each request, and requests that exceed the limit are blocked or delayed.
Fixed window algorithm — This algorithm involves counting the number of requests made within a fixed time window and blocking or delaying requests that exceed the limit.
Implementing rate limiting correctly can be challenging, as it requires balancing the need for availability and responsiveness with the need to prevent resource abuse and protect against attacks. Rate limiting needs to be carefully tuned to ensure that it does not block legitimate traffic, under-protect against attacks or cause other harm to your business.
Furthermore, rate limiting needs to be adapted to the specific requirements and characteristics of the system or service being protected. For example, a service with high peak loads may require different rate-limiting strategies than a service with consistent, low-level traffic.
Что такое ошибка 429
Ошибка 429 «слишком много запросов» является ошибкой, которая возникает при работе с веб-сервисами или API, когда клиент отправляет слишком много запросов за короткое время. Эта ошибка представляет собой ограничение и защитный механизм, реализованные сервером для предотвращения перегрузки и уменьшения нагрузки на сервер.
При получении ошибки 429, сервер отправляет клиенту специальный код состояния HTTP 429 Too Many Requests, чтобы указать, что доступ к ресурсу временно ограничен из-за избыточного количества запросов. Этот код состояния указывает на то, что клиент должен уменьшить частоту отправки запросов или воспользоваться другим способом доступа к ресурсу.
Ошибка 429 может быть вызвана несколькими причинами:
- Отправка слишком большого количества запросов в краткий промежуток времени
- Превышение лимитов или ограничений, установленных сервером для конкретного пользователя или приложения
- Неправильная настройка клиента или программного обеспечения, которое отправляет запросы
- Использование неэффективных запросов или неоптимальных алгоритмов обращения к ресурсу
Чтобы исправить ошибку 429, следует принять следующие меры:
- Уменьшить частоту отправки запросов. Если сервер ограничивает количество запросов в заданный промежуток времени, формулируйте запросы более тщательно.
- Использовать кэширование запросов, чтобы уменьшить количество обращений к серверу.
- Проверить лимиты или ограничения, установленные сервером, и соблюдать их.
- Избегать ненужных или избыточных запросов, оптимизируя код и алгоритмы обращения к ресурсу.
- Если ошибка 429 возникает в результате неправильной настройки клиента, проверьте настройки и следуйте рекомендациям сервера или провайдера API.
Знание причин и методов устранения ошибки 429 поможет повысить эффективность работы с веб-сервисами и API и избежать проблем, связанных с перегрузкой серверов и ограничениями доступа.
Проверить правильность ввода данных
Ошибки при вводе данных являются одной из наиболее распространенных проблем, с которыми сталкиваются пользователи в интернете. Проверка правильности ввода данных помогает уменьшить число таких ошибок и обеспечить корректную работу веб-приложений.
Существует несколько способов проверки правильности ввода данных:
Проверка на пустое значение
При вводе данных в форму, важно проверить, что все обязательные поля заполнены. Если какое-либо поле остается пустым, пользователю следует вывести сообщение об ошибке и попросить заполнить его
Это можно сделать с помощью JavaScript, добавив условие на пустое значение перед отправкой формы на сервер.
Проверка на правильный формат. Некоторые поля требуют определенного формата данных, например, поля «телефон» или «email». В таких случаях важно проверить, что пользователь ввел данные в правильном формате. Для этого можно использовать регулярные выражения, которые проверят соответствие введенных данных заданному шаблону.
Проверка на допустимый диапазон значений. В некоторых случаях необходимо проверить, что введенное значение находится в определенном диапазоне. Например, при вводе даты можно проверить, что она находится в диапазоне от текущей даты до определенной будущей даты.
Проверка правильности ввода данных является важным этапом разработки веб-приложений. Она позволяет улучшить пользовательский опыт и уменьшить число ошибок, которые могут возникнуть при обработке пользовательских данных.
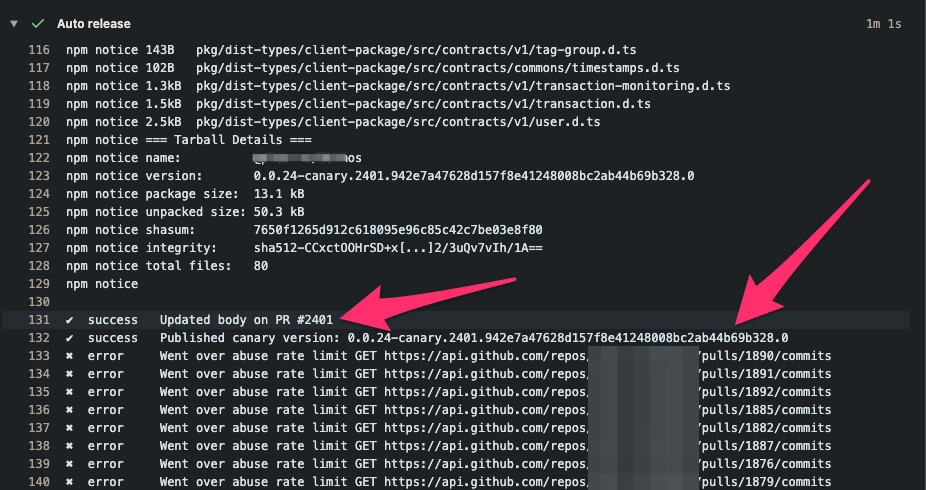
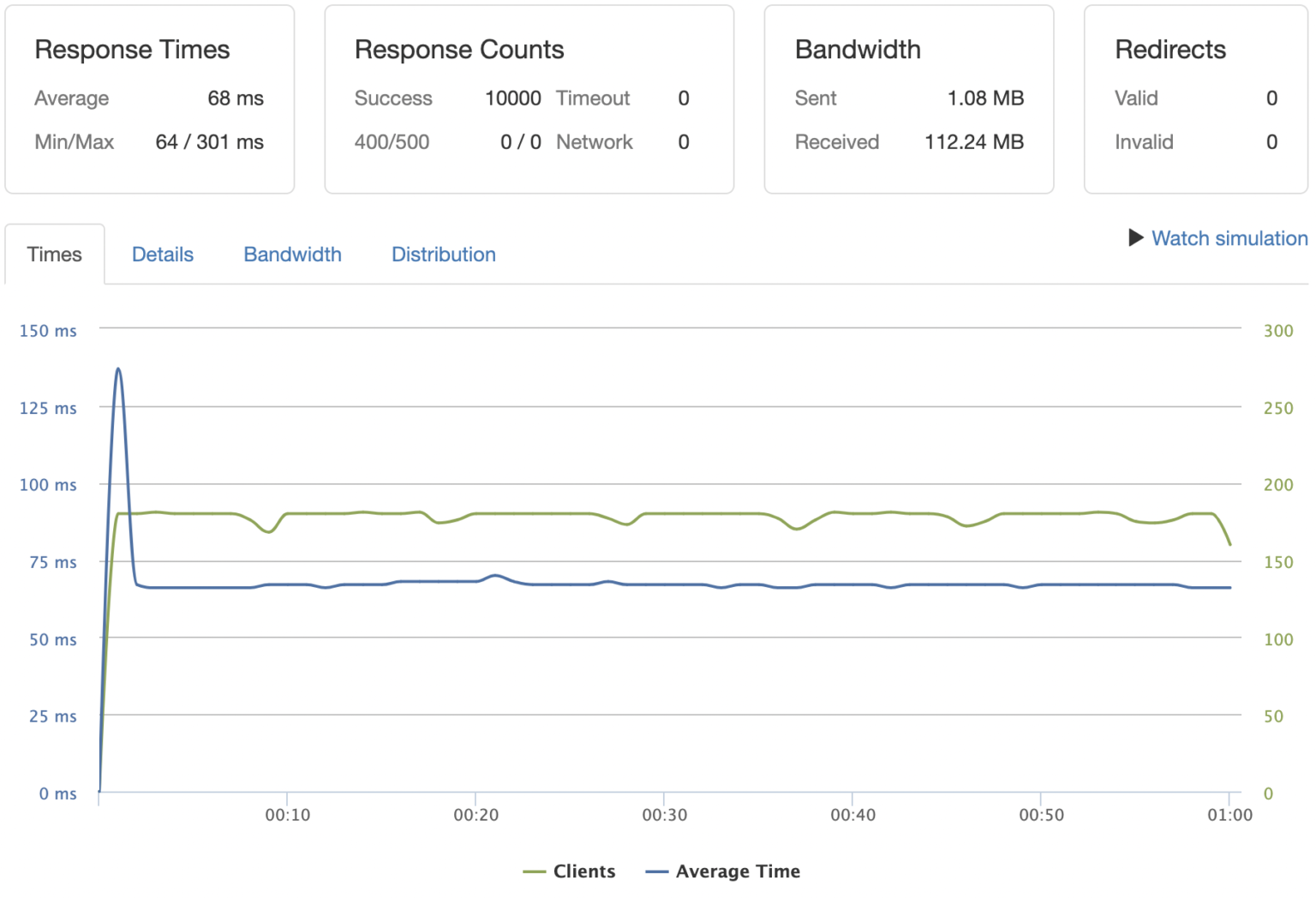
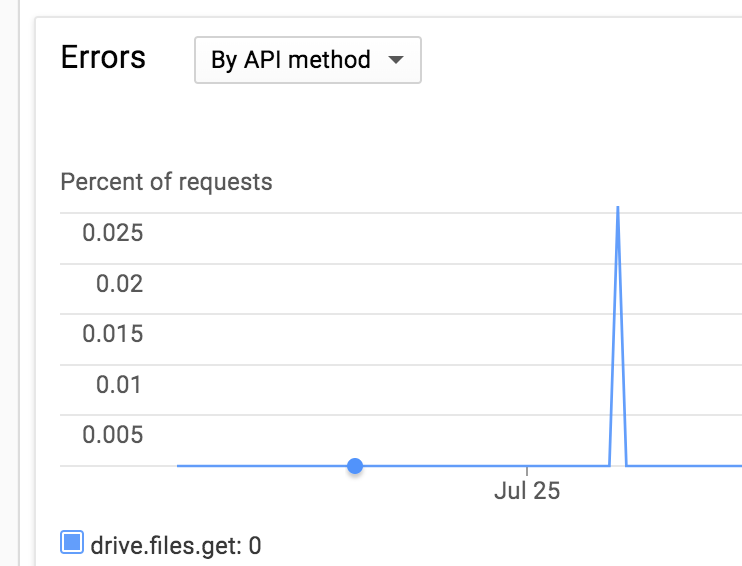

Object lock timeouts
Integrations may encounter errors with HTTP status , code , and this message:
The Stripe API locks objects on some operations so that concurrent workloads don’t interfere and produce an inconsistent result. The error above is caused by a request trying to acquire a lock that’s already held elsewhere, and timing out after it couldn’t be acquired in time.
Lock timeouts have a different cause than rate limiting, but their mitigations are similar. As with rate limiting errors, we recommend retrying on an exponential backoff schedule (see ). But unlike rate limiting errors, the automatic retry mechanisms built into Stripe’s client libraries retry s caused by lock timeouts:
Ruby
Lock contention is caused by concurrent access on related objects. Integrations can vastly reduce this by making sure that mutations on the same object are queued up and run sequentially instead. Concurrent operations against the API are still okay, but try to make sure simultaneous operations operate only on unique objects. It’s also possible to see lock contention caused by a conflict with an internal Stripe background process—this should be rare, but because it’s beyond user control, we recommend that all integrations are able to retry requests.
Gotchas and Good Practices When Implementing Client-side Rate Limiting
Make the Rate Limiter a Singleton
All calls to a given remote service should go through the same instance. For a given remote service the must be a singleton.
If we don’t enforce this, some areas of our codebase may make a direct call to the remote service, bypassing the . To prevent this, the actual call to the remote service should be in a core, internal layer and other areas should use a rate-limited decorator exposed by the internal layer.
How can we ensure that a new developer understands this intent in the future? Check out Tom’s article which shows one way of solving such problems by organizing the package structure to make such intents clear. Additionally, it shows how to enforce this by codifying the intent in ArchUnit tests.
Configure the Rate Limiter for Multiple Server Instances
Figuring out the right values for the configurations can be tricky. If we are running multiple instances of our service in a cluster, the value for must account for this.
For example, if the upstream service has a rate limit of 100 rps and we have 4 instances of our service, then we would configure 25 rps as the limit on each instance.
This assumes, however, that the load on each of our instances will be roughly the same. If that’s not the case or if our service itself is elastic and the number of instances can vary, then Resilience4j’s may not be a good fit.
In that case, we would need a rate limiter that maintains its data in a distributed cache and not in-memory like Resilience4j . But that would impact the response times of our service. Another option is to implement some kind of adaptive rate limiting. While Resilience4j may support it in the future, it is not clear when it will be available.
Choose the Right Timeout
For the configuration value, we should keep the expected response times of our APIs in mind.
If we set the too high, the response times and throughput will suffer. If it is too low, our error rate may increase.
Since there could be some trial and error involved here, a good practice is to maintain the values we use in like , , and as a configuration outside our service. Then we can change them without changing code.
Tune Client-side and Server-side Rate Limiters
Implementing client-side rate limiting does not guarantee that we will never get rate limited by our upstream service.
Suppose we had a limit of 2 rps from the upstream service and we had configured as 2 and as 1s. If we make two requests in the last few milliseconds of the second, with no other calls until then, the would permit them. If we make another two calls in the first few milliseconds of the next second, the would permit them too since two new permissions would be available. But the upstream service could reject these two requests since servers often implement sliding window-based rate limiting.
To guarantee that we will never get a rate exceeded from an upstream service, we would need to configure the fixed window in the client to be shorter than the sliding window in the service. So if we had configured as 1 and as 500ms in the previous example, we would not get a rate limit exceeded error. But then, all the three requests after the first one would wait, increasing the response times and reducing the throughput. Check out this video which talks about the problems with static rate limiting and the advantages of adaptive control.